


Original source: medium.com/@huidou/lets-understand-chrome-v..
Welcome to other chapters of Let’s Understand Chrome V8
This paper explains the generation of the two token words function JsPrint, and shows the kernal code, workflow and important data structures of the scanner.
1. Test Case
Note: The test case is very simple, so it can’t cover the full flow of the scanner.
function JsPrint(a){
if(a >5){
return "Debug";
}
}
console.log(JsPrint(6));
2. Token: function, JsPrint
The V8INLINE Token::Value Scanner::ScanSingleToken() is the start of scanning the token. We already know that c0 has already pointed to the first character of the JS stream during initializtion. In our test case, c0_ points to “f”. Let’s see how it works.
1. V8_INLINE Token::Value Scanner::ScanSingleToken() {
2. Token::Value token;
3. do {
4. next().location.beg_pos = source_pos();
5. if (V8_LIKELY(static_cast<unsigned>(c0_) <= kMaxAscii)) {
6. token = one_char_tokens[c0_];
7. switch (token) {
8. case Token::LPAREN:
9. case Token::RPAREN:
10. case Token::LBRACE:
11. case Token::RBRACE:
12. case Token::LBRACK:
13. case Token::RBRACK:
14. case Token::COLON:
15. case Token::SEMICOLON:
16. case Token::COMMA:
17. case Token::BIT_NOT:
18. case Token::ILLEGAL:
19. // One character tokens.
20. return Select(token);
21. case Token::CONDITIONAL:
22. // ? ?. ?? ??=
23. Advance();
24. if (c0_ == '.') {
25. Advance();
26. if (!IsDecimalDigit(c0_)) return Token::QUESTION_PERIOD;
27. PushBack('.');
28. } else if (c0_ == '?') {
29. return Select('=', Token::ASSIGN_NULLISH, Token::NULLISH);
30. }
31. return Token::CONDITIONAL;
32. case Token::STRING:
33. return ScanString();
34. case Token::LT:
35. // < <= << <<= <!--
36. Advance();
37. if (c0_ == '=') return Select(Token::LTE);
38. if (c0_ == '<') return Select('=', Token::ASSIGN_SHL, Token::SHL);
39. if (c0_ == '!') {
40. token = ScanHtmlComment();
41. continue;
42. }
43. return Token::LT;
44. case Token::GT:
45. // > >= >> >>= >>> >>>=
46. Advance();
47. if (c0_ == '=') return Select(Token::GTE);
48. if (c0_ == '>') {
49. // >> >>= >>> >>>=
50. Advance();
51. if (c0_ == '=') return Select(Token::ASSIGN_SAR);
52. if (c0_ == '>') return Select('=', Token::ASSIGN_SHR, Token::SHR);
53. return Token::SAR;
54. }
55. return Token::GT;
56. case Token::ASSIGN:
57. // = == === =>
58. Advance();
59. if (c0_ == '=') return Select('=', Token::EQ_STRICT, Token::EQ);
60. if (c0_ == '>') return Select(Token::ARROW);
61. return Token::ASSIGN;
62. case Token::NOT:
63. // ! != !==
64. Advance();
65. if (c0_ == '=') return Select('=', Token::NE_STRICT, Token::NE);
66. return Token::NOT;
67. //........................
68. //omit
69. //........................
70. case Token::PERIOD:
71. // . Number
72. Advance();
73. if (IsDecimalDigit(c0_)) return ScanNumber(true);
74. if (c0_ == '.') {
75. if (Peek() == '.') {
76. Advance();
77. Advance();
78. return Token::ELLIPSIS;
79. }
80. }
81. return Token::PERIOD;
82. case Token::TEMPLATE_SPAN:
83. Advance();
84. return ScanTemplateSpan();
85. case Token::PRIVATE_NAME:
86. if (source_pos() == 0 && Peek() == '!') {
87. token = SkipSingleLineComment();
88. continue;
89. }
90. return ScanPrivateName();
91. case Token::WHITESPACE:
92. token = SkipWhiteSpace();
93. continue;
94. case Token::NUMBER:
95. return ScanNumber(false);
96. case Token::IDENTIFIER:
97. return ScanIdentifierOrKeyword();
98. default:
99. UNREACHABLE();
100. }
101. }
102. if (IsIdentifierStart(c0_) ||
103. (CombineSurrogatePair() && IsIdentifierStart(c0_))) {
104. return ScanIdentifierOrKeyword();
105. }
106. if (c0_ == kEndOfInput) {
107. return source_->has_parser_error() ? Token::ILLEGAL : Token::EOS;
108. }
109. token = SkipWhiteSpace();
110. // Continue scanning for tokens as long as we're just skipping whitespace.
111. } while (token == Token::WHITESPACE);
112. return token;
113. }
(1): The 5th line of the above code. Checks whether c0 is an Ascii. In our case, it is true (c0 is f).
(2): The 6th line of the above code. one_char_tokens is a pre-defined template in V8, which is an array of character types. It is below:
constexpr Token::Value GetOneCharToken(char c) {
// clang-format off
return
c == '(' ? Token::LPAREN :
c == ')' ? Token::RPAREN :
//.....................
//omit
//.....................
// IsDecimalDigit must be tested before IsAsciiIdentifier
IsDecimalDigit(c) ? Token::NUMBER :
IsAsciiIdentifier(c) ? Token::IDENTIFIER :
Token::ILLEGAL;
// clang-format on
}
//====separation ========================================================
#define INT_0_TO_127_LIST(V) \
V(0) V(1) V(2) V(3) V(4) V(5) V(6) V(7) V(8) V(9) \
V(10) V(11) V(12) V(13) V(14) V(15) V(16) V(17) V(18) V(19) \
V(20) V(21) V(22) V(23) V(24) V(25) V(26) V(27) V(28) V(29) \
V(30) V(31) V(32) V(33) V(34) V(35) V(36) V(37) V(38) V(39) \
V(40) V(41) V(42) V(43) V(44) V(45) V(46) V(47) V(48) V(49) \
V(50) V(51) V(52) V(53) V(54) V(55) V(56) V(57) V(58) V(59) \
V(60) V(61) V(62) V(63) V(64) V(65) V(66) V(67) V(68) V(69) \
V(70) V(71) V(72) V(73) V(74) V(75) V(76) V(77) V(78) V(79) \
V(80) V(81) V(82) V(83) V(84) V(85) V(86) V(87) V(88) V(89) \
V(90) V(91) V(92) V(93) V(94) V(95) V(96) V(97) V(98) V(99) \
V(100) V(101) V(102) V(103) V(104) V(105) V(106) V(107) V(108) V(109) \
V(110) V(111) V(112) V(113) V(114) V(115) V(116) V(117) V(118) V(119) \
V(120) V(121) V(122) V(123) V(124) V(125) V(126) V(127)
//====separation ========================================================
static const constexpr Token::Value one_char_tokens[128] = {
#define CALL_GET_SCAN_FLAGS(N) GetOneCharToken(N),
INT_0_TO_127_LIST(CALL_GET_SCAN_FLAGS)
#undef CALL_GET_SCAN_FLAGS
};
The one_char_tokens is composed of the above three parts of the code. In our case, ‘f’ is the IsAsciiIdentifier(c) identifier, it’s type is Token::IDENTIFIER, and IsAsciiIdentifier is below:
inline constexpr bool IsAsciiIdentifier(base::uc32 c) {
return IsAlphaNumeric(c) || c == '$' || c == '_';
}
(3): Look at ScanSingleToken(). The type of c0_ is Token::IDENTIFIER, so the ScanIdentifierOrKeyword() will be called. We can see several methods in ScanIdentifierOrKeyword, these methods are used to wrap the relationship between classes. Figure 1 is the call stack of these methods.
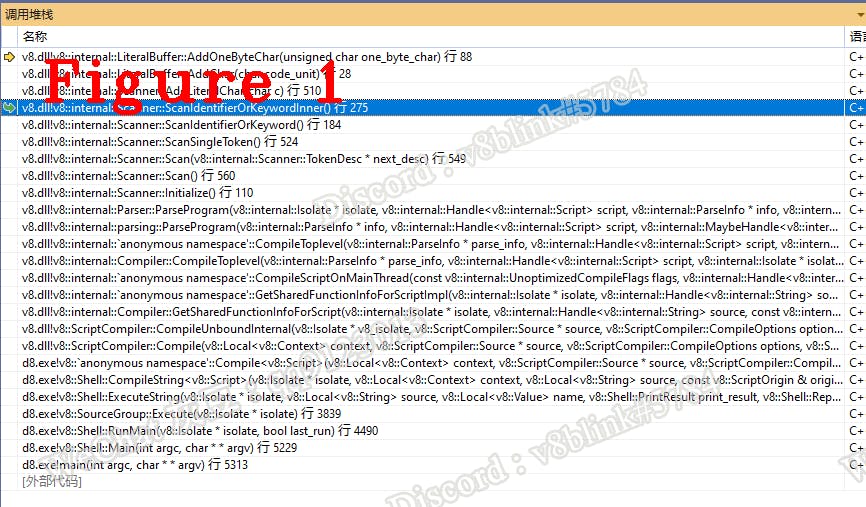 Searching for ScanSingleToken in V8, then set a breakpoint on it, you can reproduce the stack of Figure 1.
Searching for ScanSingleToken in V8, then set a breakpoint on it, you can reproduce the stack of Figure 1.
(4): Before scanning the next character, the ‘f’ needs to be saved. The following is the method to save characters.
V8_INLINE void AddOneByteChar(byte one_byte_char) {//c0_ is the argument
DCHECK(is_one_byte());
if (position_ >= backing_store_.length()) ExpandBuffer();
backing_store_[position_] = one_byte_char;
position_ += kOneByteSize;
}
Figure 2 is the variable window, we can see that the one_bytechar is c0, which is stored in the backingstore.
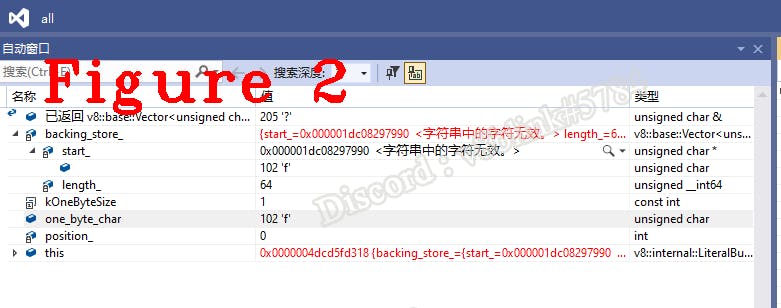 Let’s start scanning the second character, the code is bellow.
Let’s start scanning the second character, the code is bellow.
AdvanceUntil([this, &scan_flags](base::uc32 c0) {
if (V8_UNLIKELY(static_cast<uint32_t>(c0) > kMaxAscii)) {
// A non-ascii character means we need to drop through to the slow
// path.
// TODO(leszeks): This would be most efficient as a goto to the slow
// path, check codegen and maybe use a bool instead.
scan_flags |=
static_cast<uint8_t>(ScanFlags::kIdentifierNeedsSlowPath);
return true;
}
uint8_t char_flags = character_scan_flags[c0];
scan_flags |= char_flags;
if (TerminatesLiteral(char_flags)) {
return true;
} else {
AddLiteralChar(static_cast<char>(c0));
return false;
}
});
The AdvanceUntil method reads each character in turn and stops when the terminator occurs.
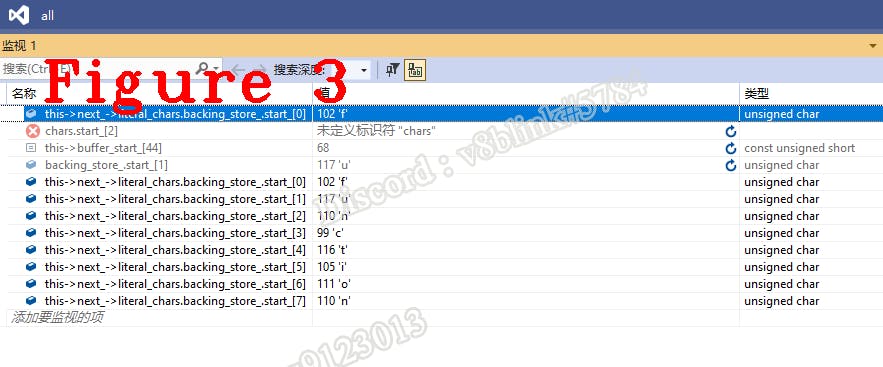 In Figure 3, we can see that these eight characters are exactly the first string — — function in our case. Now, we get a complete token, the next step is to analyze whether the token is a keyword or an identifier. The code is bellow.
In Figure 3, we can see that these eight characters are exactly the first string — — function in our case. Now, we get a complete token, the next step is to analyze whether the token is a keyword or an identifier. The code is bellow.
V8_INLINE Token::Value KeywordOrIdentifierToken(const uint8_t* input,
int input_length) {
DCHECK_GE(input_length, 1);
return PerfectKeywordHash::GetToken(reinterpret_cast<const char*>(input),
input_length);
}
//==============separation===============
inline Token::Value PerfectKeywordHash::GetToken(const char* str, int len) {
if (base::IsInRange(len, MIN_WORD_LENGTH, MAX_WORD_LENGTH)) {
unsigned int key = Hash(str, len) & 0x3f;
DCHECK_LT(key, arraysize(kPerfectKeywordLengthTable));
DCHECK_LT(key, arraysize(kPerfectKeywordHashTable));
if (len == kPerfectKeywordLengthTable[key]) {
const char* s = kPerfectKeywordHashTable[key].name;
while (*s != 0) {
if (*s++ != *str++) return Token::IDENTIFIER;
}
return kPerfectKeywordHashTable[key].value;
}
}
return Token::IDENTIFIER;
}
GetToken is used to determine whether a token is a keyword or an identifier. The determination is very simple — get the type of token by looking up a predefined hash table. Figure 4 shows the important members of the hash table.
 So far, the token function has been generated, and it’s type is Token::FUNCTION. The token JsPrint is similar, it’s type is Token::IDENTIFIER.
So far, the token function has been generated, and it’s type is Token::FUNCTION. The token JsPrint is similar, it’s type is Token::IDENTIFIER.
3. Difference between function and JsPrint
We know that function is a keyword, and JsPrint is a custom identifier. Let’s see how Parser expresses the difference between the two of them.
ParserBase<Impl>::ParseHoistableDeclaration(
int pos, ParseFunctionFlags flags, ZonePtrList<const AstRawString>* names,
bool default_export) {
CheckStackOverflow();
DCHECK_IMPLIES((flags & ParseFunctionFlag::kIsAsync) != 0,
(flags & ParseFunctionFlag::kIsGenerator) == 0);
if ((flags & ParseFunctionFlag::kIsAsync) != 0 && Check(Token::MUL)) {
// Async generator
flags |= ParseFunctionFlag::kIsGenerator;
}
IdentifierT name;
FunctionNameValidity name_validity;
IdentifierT variable_name;
if (peek() == Token::LPAREN) {
if (default_export) {
impl()->GetDefaultStrings(&name, &variable_name);
name_validity = kSkipFunctionNameCheck;
} else {
ReportMessage(MessageTemplate::kMissingFunctionName);
return impl()->NullStatement();
}
} else {
bool is_strict_reserved = Token::IsStrictReservedWord(peek());
name = ParseIdentifier();
name_validity = is_strict_reserved ? kFunctionNameIsStrictReserved
: kFunctionNameValidityUnknown;
variable_name = name;
}
FuncNameInferrerState fni_state(&fni_);
impl()->PushEnclosingName(name);
FunctionKind function_kind = FunctionKindFor(flags);
FunctionLiteralT function = impl()->ParseFunctionLiteral(
name, scanner()->location(), name_validity, function_kind, pos,
FunctionSyntaxKind::kDeclaration, language_mode(), nullptr);
//omit.......
//.........
The above code parses these two tokens. Let’s make it clear that the scanner is responsible for generating tokens, and the difference between tokens is identified by the parser.
typename ParserBase<Impl>::IdentifierT ParserBase<Impl>::ParseIdentifier(
FunctionKind function_kind) {
Token::Value next = Next();
if (!Token::IsValidIdentifier(
next, language_mode(), IsGeneratorFunction(function_kind),
flags().is_module() ||
IsAwaitAsIdentifierDisallowed(function_kind))) {
ReportUnexpectedToken(next);
return impl()->EmptyIdentifierString();
}
return impl()->GetIdentifier();
}
In ParserBase::ParseHoistableDeclaration(), the above method will be called. In our case, the ParseIdentifier uses the following symbol method when parsing our function and JsPrint.
V8_INLINE const AstRawString* GetSymbol() const {
const AstRawString* result = scanner()->CurrentSymbol(ast_value_factory());
DCHECK_NOT_NULL(result);
return result;
}
The symbol table saves the correspondence between identifiers and JS source code. Precisely, it saves the pairing relationship between the identifier and it’s declaration information. In our case, the function and JsPrint are a pair in the symbol table. Figure 5 is the call stack of the symbol table.
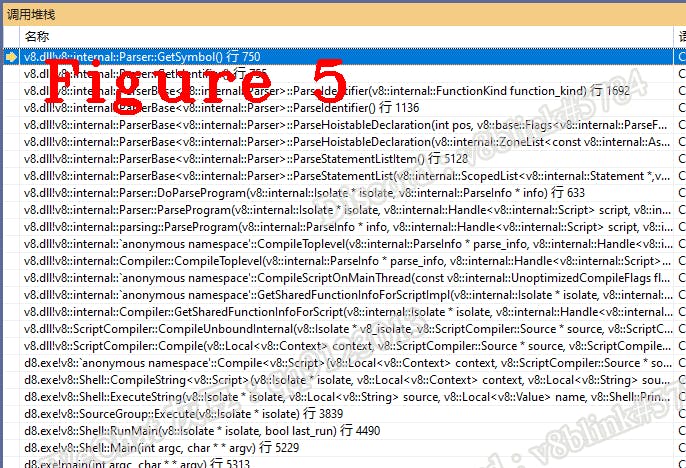 We can see the source code when debugging the program, precisely benefit from the existence of the symbol table. It is a data structure generated in the compilation. To be precise, the symbol table is generated in the lexical analysis phase and supplemented in the syntax analysis phase.
We can see the source code when debugging the program, precisely benefit from the existence of the symbol table. It is a data structure generated in the compilation. To be precise, the symbol table is generated in the lexical analysis phase and supplemented in the syntax analysis phase.
Okay, that wraps it up for this share. I’ll see you guys next time, take care!
Please reach out to me if you have any issues. WeChat: qq9123013 Email: v8blink@outlook.com